Module 1 : Foundations
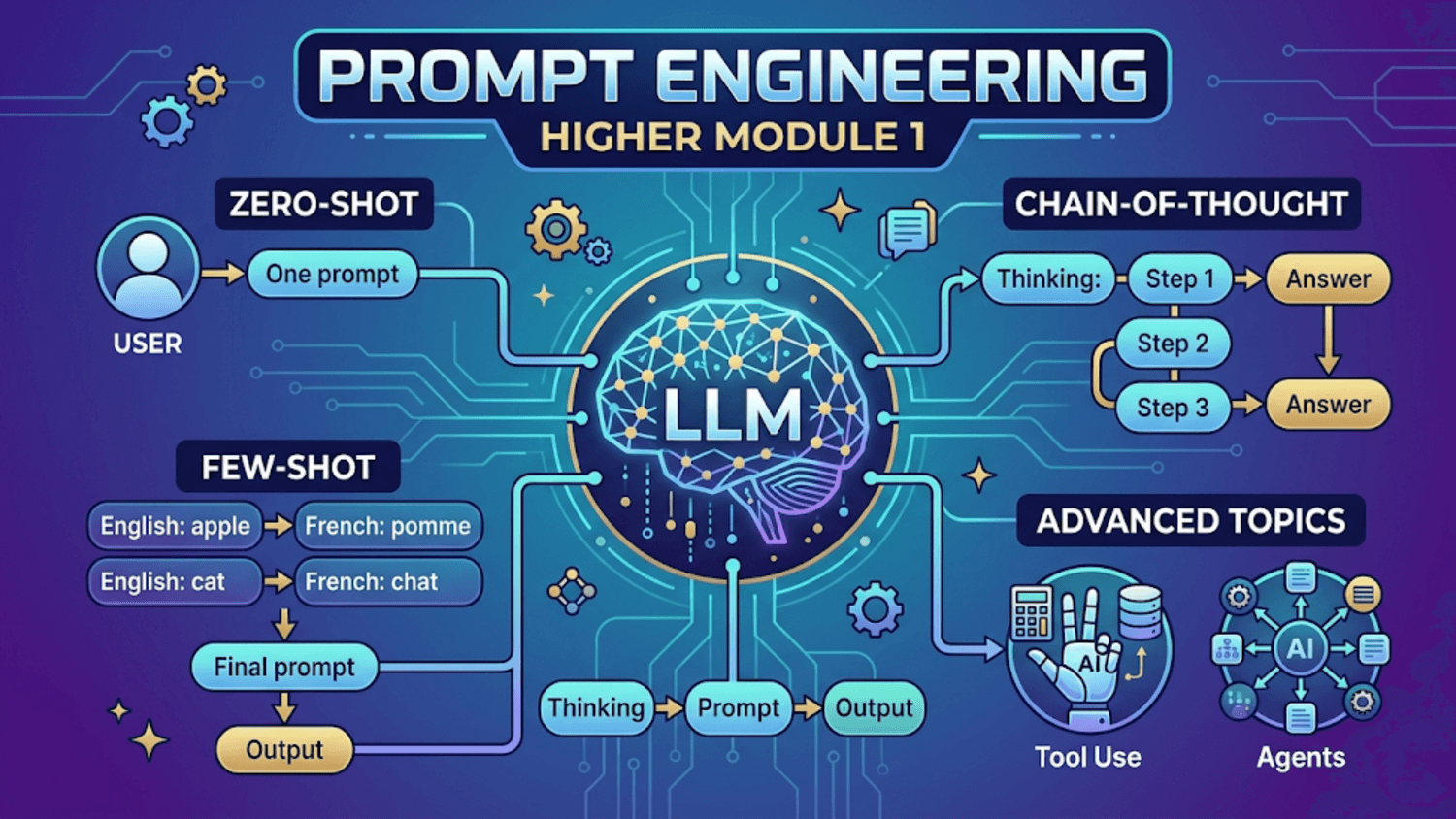
Core Definition of AI: A Large Language Model (LLM) is a "prediction engine" that generates statistically plausible text by predicting the next word in a sequence. It does not understand, reason, or verify information.
The "Hallucination" Problem: AI can confidently generate false information, known as "hallucinations," which are an inherent feature of how LLMs work, not a bug. It cannot distinguish truth from falsehood, making verification a mandatory step for users.
The Safety-Critical Mindset: The course advocates for a six-principle mindset adapted from fields like air traffic control to ensure responsible AI use: Unambiguous Instruction, Anticipation of Outcomes, Failure Mode Thinking, Verification, Assumption Interrogation, and Maintained Judgment.
Cost of Vague Prompts: Vague prompts force the AI to fill gaps with generic, often incorrect, assumptions about context (e.g., class duration, resources), leading to outputs that are misaligned and require significant revision.
Use vs. Integration: The course distinguishes between casual, improvised "use" of AI and intentional, systematic, and verified "integration" into professional workflows, which is the ultimate goal